The Constraint of a system, in a nutshell, is "the most limiting factor." By definition, it determines the capacity of the entire system: if the Constraint is underutilized, the entire system is underutilized. However, if the Constraint is overburdened, no amount of additional input into the system will lead to more output. Many organizations struggle with this - and that has dire consequences!
Let's start by taking a quick glance at the Constraint:

In our example, the third step (C) is the Constraint - because it has the minimum capacity in our system. An important consideration is that we're not talking about investment or staffing here, our concern is the ability to generate throughput.
As an example, if we have a single A costing $100k to generate 50 Throughput, but ten C costing $1m to generate 30 Throughput, then the Constraint is C, not A.
This simple truth has tremendous consequences:
Don't work more than necessary

- Excess capacity behind the Constraint is "idle." It exists, but can't generate throughput. Adding more capacity at this point has no effect.
- Excess idle capacity in front of the Constraint doesn't generate throughput.
- Excess busy capacity in front of the Constraint adds overburden to the Constraint!
The third point is critical - because of the consequences: Let's say our Constraint is a specialist, and work is piling up at their doorstep. Work waiting at the Constraint generates no value for our company. Since someone was asking for that work in wait, these people will start wondering when their request gets served, i.e. they become unhappy. Eventually, the Constraint will be tasked with managing their undone inventory. At a minimum, some capacity gets diverted away from doing actual work - into managing work. At worst, it will reduce their capacity with each piece of work in wait, until they are fully incapacitated and spend their entire time in status meetings, explaining why nothing gets done.
And that brings up an important question:
Assuming you are not the Constraint: should you optimize your own work?
The astonishing answer is: No. And here's why.
Where's your Constraint?

- You're stream-aligned. The only people depending on you are the customers.
- You're behind the Constraint. There's someone, or something, that determines how much work arrives at your desk, and you get less work than you could do.
- You're before the Constraint. The more you work, the bigger the "waiting for" the Constraint pile grows.
- You and others are working in parallel. What you do, they don't. What they do, you don't need to.
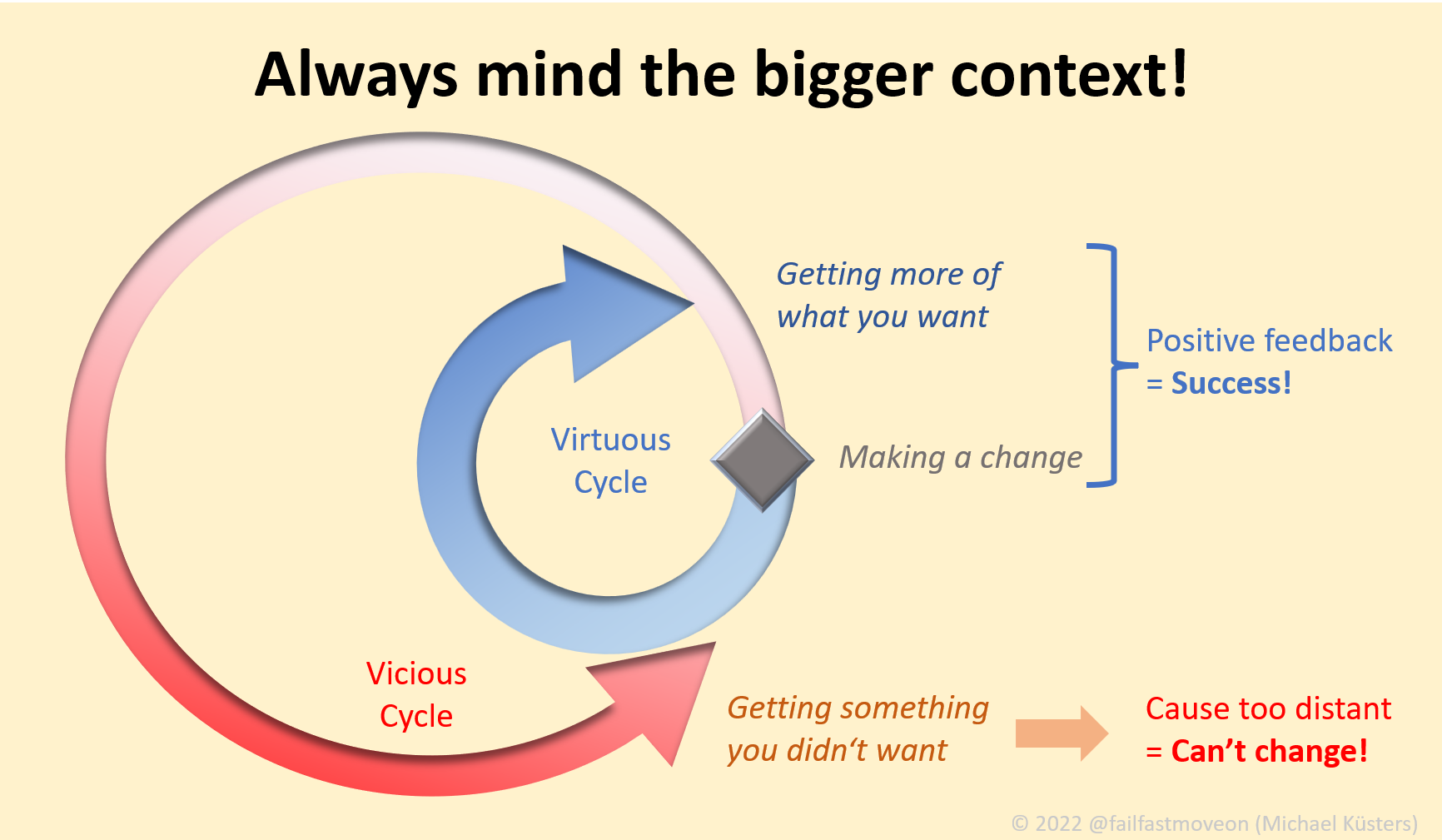
The image doesn't display the scenario that you are operating at the Constraint, because that's equivalent to being unconstrained: the more you do, the more throughput you get. So - let's examine the above four scenarios.
In scenario 1, you are operating as if you were the Constraint, until you get into a "Before" or "Behind" scenario by overburdening your customers. Here, improvement works in everyone's favor until customers start to scream.
In scenario 2 - you have excess capacity anyways. Customer throughput is limited by the Constraint, so the only thing you can spend your optimized capacity on would be gold-plating. At best, nobody notices. At worst, you'll get scolded for wasting company assets. In any case, your optimization efforts won't win you a medal.
In scenario 3 - your capacity outmatches the Constraint. If you want to optimize the Whole: do less. You can only make a difference by reducing burden on the Constraint, that is: by taking work away from them. If you optimize in ways that allow you to do more work, you'll either get scolded if that makes you idle, or your extra work won't lead to extra customer value. In the latter case, you'll get scolded for not delivering more (even though you did, but the customer doesn't see that.)
When optimization doesn't work
In scenario 4, you're acting similar to scenario 1 - you're essentially the Constraint yourself and optimize accordingly.
That leaves scenarios 2 and 3. In both scenarios, you lose by winning.
Any optimization you do when you're not the Constraint will evaporate, be invisble, or make things worse for the Constraint, and thus for the system, and thus, in extension: for you.
When teams try their best to optimize their ways of working, and see that it either does nothing, or backfires - eventually, they get change fatigue: "Why should we change anything that doesn't help us?"
And that's a core problem with Scrum: The Scrum Guide suggests that teams should identify improvements in every single Retrospective, without considering whether the team is even the Constraint. If you aren't - you won't see anything coming out of your changes. To make Retrospectives meaningful, identifying and enacting change is insufficient. You have to make sure that the changes are actually beneficial to the organization as a whole.
What now?
Here are four simple checks you can do:
- If you are the Constraint, do whatever it takes. Do less, do more. Simpler. Faster. Better. It will be noticable immediately, and you may even generate massive leverage. If you're five, and you have 100 people in your organization, every minute you save will have a twenty-fold impact. You'll be celebrated like heroes for even minor improvements.
- If you're pushing work "downstream" for other teams to pick up, and you see work piling up, do not try to discover ways to do more: Do less. Use the free capacity to pick up work that would otherwise happen downstream.
- If you're not receiving enough input from "upstream," don't try to do whatever you do better. Instead, pick up work that would otherwise happen upstream.
- If you see that "downstream" is challenged, and you receive flowback, i.e. defects, complaints, questions or anything that makes downstream wait for you, then you have to improve how you work, so that there's less work to do downstream.