SAFe4 suggests that Story Points should be normalized across the Release Train. Additionally, it provides a method for estimating the first Sprint that could be considered inconsistent with the idea of Story Points. Let us take a closer look at the idea.
What are Story Points?
Story Points are, in short, an arbitrary measure quantifying the expected effort to get a backlog item "Done". They are expected to help the team plan their capacity for each iteration and to help the Product Owner in getting a rough understanding of how much the team might be able to deliver within the few next months. This can be used, for example, to calculate estimated Release dates and/or scope.
There is an additional purpose that is also suggested by Mike Cohn in his blog: When you know the amount of Story Points that can be completed per Iteration, you can assign cost estimates to backlog items helping the PO make better business decisions.
For example, a backlog item might turn into a negative business case once the cost is known, and can then either be reworked for better ROI or discarded entirely.
SAFe picks up this idea in the
WSJF concept, i.e. prioritizing features that have a good ROI/effort ratio.
The most important thing about Story Point estimation is that every member within the team has an understanding of what a Story Point means to the team. It can mean something entirely different things to other teams, hence caution should be exercised when they are referenced outside the team.
What are Normalized Story Points?
SAFe's delivery unit is the Agile Release Train (ART), effectively a "Team of Teams".
Just as a Story Point is intended to mean the same thing to one team, it should mean the same thing within a Team of Teams.
Otherwise, the Product Manager would receive different estimates from different teams and is completely unable to use these estimates for business purposes. This would render the estimation process useless and estimates worthless.
As such, SAFe suggests that just like in a Scrum team, the individual team members need a common understanding of their Story Points - the ART's individual teams require a common understanding of their Story Points to make meaningful estimates.
Why can't each team have their own Story Points?
In SAFe, all teams on the Release Train pull their work from a single, shared, common, central Program Backlog. This Program Backlog serves to consolidate all work within the ART, regardless of which team will actually pull the work.
A key Agile concept is that the work should be independent of the person who does it, as specialization leads to local optimization.
From a Lean perspective, it is better if a slower team starts the work immediately than to wait for a faster team.
Especially when cross-team collaboration is an option, the slower team can already deliver a portion of the value before the faster team becomes available to join the collaboration. This reduces the overall time that the faster team is bound and hastens final completion.
If Story Points differ among teams, it might become necessary that every single backlog item needs to be estimated by every single team in order to see
which team takes
how long to complete the item. This type of estimation is possible, yet leads to tremendous waste and overhead.
If Story Points are normalized across teams, it is sufficient to get a single estimate from a single team, then look at the velocity of each team to get an understanding which team would take how long.
Another benefit of normalized Story Points is that when Team A needs support from Team B to meet a crucial deadline, Team B's product Owner knows exactly how much they need to drop from the backlog in order to take on some stories from Team A without wasting effort on re-estimation.
How does SAFe normalize Story Points?
In the first Program Increment, the ART is new. Both the individual teams and the ART consist of members who have not collaborated in this constellation before. Teams are in the "Storming" phase - as is the ART itself.
This means Working Agreements are unclear. The DOD is just a vague ideal that hasn't been applied before and might have unexpected pitfalls. Depending on the product work, the environment is also new and unknown. Effectively, the teams don't know anything about how much work they can do. Every estimate is a haphazard guess.
One approach might be to have a discussion first to identify a benchmark story, assign benchmark points and work from there. This discussion will lead to further discussions, all of which provide no customer value.
To avoid this approach, SAFe suggests the following approach:
Start with Relative Estimates
In the first PI Planning, teams take the smallest item in their backlog and assign it a "1". Then, using Relative Estimation (based on Fibonacci numbers), they assign a "2" to the next bigger item, a "3" to an item that is slightly bigger than that one - and so on. Once, they have a couple of references, they can say "About as much as this/that one".
Of course - all of this is guesswork. But it's as good as any other method in the absence of empirical data. At least teams get to have a healthy discussion about "what", "how" and potential risks.
How is Velocity calculated based on Normalized Story Points?
Again, in the first Program Increment, we have absolutely no idea how many Story Points a team can deliver. Since we have rough Person-day estimates, SAFe suggests a very simplistic approach for the first PI Planning:
We know how many team members we have and we also know how many days they *expect* to be working during the Iteration. (nobody knows when they will be sick, so that's a risk we just take).
A typical SAFe Iteration is 2 calendar weeks, so it has 10 Working Days. We multiply that number with the amount of team members.
Base Capacity = 10*Team Members
From that iteration capacity, we deduct every day of a team member's absence.
Adjusted Capacity = Base Capacity - (Holidays * Team Members ) - (Individual Absence)
Finally, we deduct 20% - as planning for 100% utilization is planning for disaster. We round this down.
Initial Velocity = Adjusted Capacity * 0.8
Here is an example:
Team Trolls has 6 developers. There is a single day of vacation and Tony needs to take care of something on Friday.
Base Capacity = 10*6 = 60 SP
Adjusted Capacity = 60 SP (Base) - 1*6 SP (Holidays) - 1 SP (Absence) = 53 SP
Velocity = 53 SP * 80% = 42 SP
So, Team Trolls would plan Iteration 1 with 42 Story Points. If the numbers don't add up, it's better to err on the lower side than to over-commit. They might choose to fill the Sprint with 39 Points, for example.
What happens to Velocity and Normalized Story Points over time?
In Iteration 1, we merely guessed. Guessing is better than nothing. We learn, inspect and adapt. For example, Team Trolls has discovered that they can slice throuh Stories like butter and take on more points in the future - while Team Badgers has discovered they need to do significant support work for other teams (such as knowledge transfer), slowing them down. They would then take on fewer Story Points in subsequent Sprints.
Here is a sample of how an ART velocity may develop over time like:
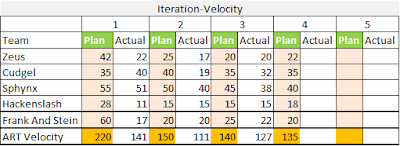 |
| Tracking velocity over time |
As we see in this example, teams Inspect+Adapt their own plan, feeding back to Product Management useful values to I+A the overall PI Plan and (if applicable) Release plans.
No re-estimation of previously estimated backlog will be needed. As new work becomes available, and "Done" Stories can be used as benchmarks for additional backlog items in the future to keep in line with current backlog items.
Caution with Normalized Story Points
Story Points are not a business metric. Neither is Velocity. They are simplified planning metrics intended to minimize planning effort while providing sufficient confidence in the created plan.
The metrics are subject to the same constraits as in single-team Scrum, i.e. the following anti-patterns need to be avoided:
Do not:
- Assume estimates are ever "correct". They are -and remain- estimates.
- Measure progress based on "Story Points Delivered". Working Software is the Primary Measure of Progress.
- Compare teams based on their velocity. Velocity is not a performance metric.
- Optimize the ART structure based on velocity figures. An ART is a highly complex adaptive system.
- Try to maintain a constant/increasing velocity. Capacity planning is intended to minimize the risk of failure and subject to reality. Velocity is just an indicator to improve the reliability of planning.
Conclusion
The normalization of Story Points solves a problem that does not exist in a non-scaled environment, i.e. the question "What happens to overall progress when another team takes on this backlog item?"
This helps the ART shuffle backlog items among teams in order to maximize for overall product value, rather than team utilization.
In the absence of better information, we use a crude rule-of-thumb to get the first Story Point figures on our backlog. When we have completed stories, we can determine which of these as useful as reference points. The initial tie between a Story Point and a developer-day moves towards a rather intangible virtual unit really quick. This
must happen to keep the Story Points consistent across teams.
The understanding of a Story Point needs to remain consistent across teams.
In the absence of better information, we use a crude rule-of-thumb to get initial team velocity. When we have completed an iteration, we use the real results as reference points for the future.
Within a few iterations, velocity's correlation to capacity-days shifts towards the intangible virtual unit of Story Points that are disconnected from time. This
must happen to maintain Velocity as a functional, consistent planning tool in the ART.
In an ART, it is even harder than in Single-team Scrum to resist the urge to evaluate teams based on Velocity. The RTE has the important responsibility to maintain the integrity of Story Points by stopping any attempts (usually by management) to abuse them.










