"Agile" is not a silver bullet. The domain is broad, wide and extremely context sensitive. Often, the intricate nuances make or break an approach.
I share my experiences for your reflection.
It's 2025, more than a decade since Story Points should have been buried. But they still aren't.
Let me tell you why they're a distraction, not a solution.
The purpose of Estimation: Decisions
When Estimates come up, I always ask: "Who needs the estimate, and what decisions will be made based on them?"
Let me give you a few examples when estimation can't be answered by providing a Story Point number:
"I need to know whether we can afford this. Can you tell me how much it costs?"
"We need to plan for contingency in case this is late. Can you do it on time?"
"Would it make sense to distribute the work across multiple teams to get it done faster?"
"Is this the simplest thing we can do to reach our goal? Does it make sense to take a shortcuts?"
"How big is the risk of failure to deliver on time, in quality by deadline?"
Did you realize that none of these questions need to be asked inside the team - and none of them relate to "Agile?"
Business-facing, not team-facing
When the only party depending on the estimate is the team, internally - why do you even estimate?
There is no criticality, no risk, no dependency, no impediment. Just do it. Best you can do, as soon as you can deliver. That's enough.
But - for the business, that is not enough.
None of the questions suggested above are relevant inside the team: their relevance is defined outside the team.
With your stakeholders, the people who pay your bills. If they can't make a proper decision, you're alienating them, risking a communication gap that could cost you your credibility.
Stakeholders don't need to know if something is 12 or 49 Story Points. They don't care if something is a Story or an Epic.
What they care is, "Do I need to adjust anything? Will I get what I need, when I need it, how I need it - at a price I can afford?"
These questions can not be answered by Story Points, unless you clearly relate Story Points back to team days and money. But if you do that - then why use them to begin with?
Estimation that doesn't drive business decisions is waste.
Customer decisions, not team decisions
What many Scrum teams and Scrum Masters fail to understand: business requires planning, too.
Your sales team must give an account to your customers if they get what they signed up for. Your customers must plan their budget, and how they use their resources.
Let me give you an example: If you buy a Mobile phone, you want to know when you can use it.
Customers don't accept "You get it when you get it" - they'll most likely leave the shop and take your money elsewhere.
And the answer, "We still need 17 Story Points until you can use it" would immediately trigger the question, "And how long is a Story Point, exactly? Minutes, Hours, Weeks?"
Estimation that pushes uncertainty to the customer is an antipattern.
Conclusion
Before you talk about which estimation method to use, try understanding your stakeholders:
Learn what your answer causes for them. Understand which decisions they will make with the information you provide.
Use the estimation approach that helps you come to a common understanding with your stakeholders.
Sometimes, "No problem, you'll have it by the end of next week" is all the information required.
When possible, skip estimation entirely - just make sure you're confident that you can live up to your promises.
But when you need to estimate: find out for whom, what they need, and give them that. And use the approach that makes you confident your answer is trustworthy.
Your job is to make the business successful, not to "do Estimation correctly."
Although I am a proponent of "#noestimates," that is - the concept that estimation is often the consequence of unsound mental models, and in itself somewhat wasteful, because we often don't know - I still propose an estimation technique that is as useful as it is simple. BUT - it requires context. Let's epxlore this context:
Problems with estimation
Regardless of how we put it, one major challenge is that many organizations use estimates as if there was certainty that they can become "correct" - which is a common dysfunction, because it results in undesirable, wasteful behaviours. These could be, for example, as upfront design, padding, "challenging estimates" - and even post-hoc adjustment of the figures to match reality. None of these behaviours help us deliver a better product, and they may even impede quality or time-to-market.
All these aside: we don't know until we tried - that is, there's this thing called "the high probability of low-probability events," so regardless of how much effort we waste on trying to get those activities "right", we could still be wrong due to something we didn't factor.
These are the common reasons for the #noestimates movement which simplys reject the discipline of upfront estimation in favor of monitoring the flow of work via execution signals to gain both predictability and control. You may ask: "If estimation is so obviously flawed, then why would you propose yet another estimation technique?"
Category Errors
A common challenge teams face is that not all work is equal: Giving a trivial non-tech example, it doesn't take much expertise to realize that building a tool shack isn't the same category as building a house - and that's not the same category as building a Burj Khalifa.
By simply letting uncategorized work flow into teams, we risk that extremely large packages block the flow of urgent high-value items for a prolonged time. Hence, a first categorization into "Huge, Large, Small" does indeed make sense - The key realization is that these aren't equal.
Hence, dice estimation first categorizes work into the right bin: everything that's workable can be taken up by the team, while everything that isn't workable should be managed appropriately before being worked upon.
Six-sided dice
Story Points worked out terribly, and they led to many dysfunctions - so let's avoid that side track. Instead, let's say that we estimate items in dice values. For small items, our estimation unit would be team-days, for large items, it would be weeks, and for large items, it would be months.
That also leads us to the first logical connection: One Small Dice at 5 or 6 could already classify for a "1" on a medium dice. We could think about splitting it in two if we want to take it on. On items bigger than 5, we should exercise caution: do we understand it properly, is the cost of implementation warranted - is it really the best thing to do next?
This also applies when an item exceeds 5 on the week count - at that point, it becomes a huge dice: we might want to check a lighweight business case and pivot before proceeding.
How Dice Estimation works
Dice estimation is very easy - you simply ask, "If each day of work was a dice roll, what would be the amount of sides on our dice so that we have enough time to hit a '1' - on average - by the time we are Done?"
That is: if the team expects to be done on 2 days, they would choose 2. If they would expect 3 days, they would choose 3 - if they expect 6, it would be 6 days.
Measuring Confidence
Since dice rolls aren't linear, this form of estimation focuses on levels of confidence in completion within a predefined period of time. Hence, despite the fact that we estimate in days, dice estimation values confidence - and thereby clarity and understanding - above quantity of work.
Estimating with uncertainty
Just like a D6 doesn't mean that "we will roll 6 times, then we will have rolled a 1" - what we estimate is the amount of faces on the dice and thereby the expected amount of days that the item will be done.
Think of it like this: If you have a coin, you have a 50% chance to get heads on the first try - and while statistically, you'd expect to get at least one heads in 2 attempts, it's theoretically possible that you need to flip the coin an infinite amount of times and never get heads.
The estimate in team-days helps us manage our work on the Dailies in an efficient manner - as long as the estimated amount of days hasn't elapsed, it's safe to assume we are on track. Any item reaching and/or exceeding the estimate should be scrutinized: are we stuck, did we misunderstand something - what is going on? The "estimate," thus, isn't even estimating effort - it's forecasting a pivot-or-persevere checkpoint so that we minimize sunk cost.
Lightweight estimation
We can estimate work items either as they arrive, during refinement, or when we get busy - that doesn't even matter. The key reasons for estimation are first, avoiding category errors and second: setting up an intuitive checkpoint so that we don't run out of bounds.
With Dice Estimation, we avoid category errors and institute checkpoints in execution
Of course, you could use dice estimation during Sprint Planning or in a PI-Planning as well, but you don't even need cadences to take advantage of Dice Estimation.
Predictability and Forecasting
As we know, a dice averages at 3.5, so even if we didn't do anything yet except categorizing by dice size, we know that our backlog of workable, small items would take about 2 weeks for 3 items. Once we've done a little bit of work and know how much the completed items took, we can either run a simple Monte Carlo Simulation or apply the Law of Large Numbers to figure out how much known work we have ahead of us. The same applies to the Large and Huge dices, which gives us a fairly decent understanding of when an item might be delivered, based on backlog position.
Not a Performance Metric
The dice metaphor should make it easy to explain how neither can one measure the perfomance of a dice-roller based on how often they roll a certain number, nor does it make sense to "squeeze" estimates - the probability of guessing the right number won't increase by restricting the "allowed" numbers that can be picked. If anything, squeezing estimates would lead the team to spend more time on examining exceptions - hence, reducing performance.
Why you should switch from Story Points to Dices
Dice Estimation is a minimum effort method of right-sizing work that helps with:
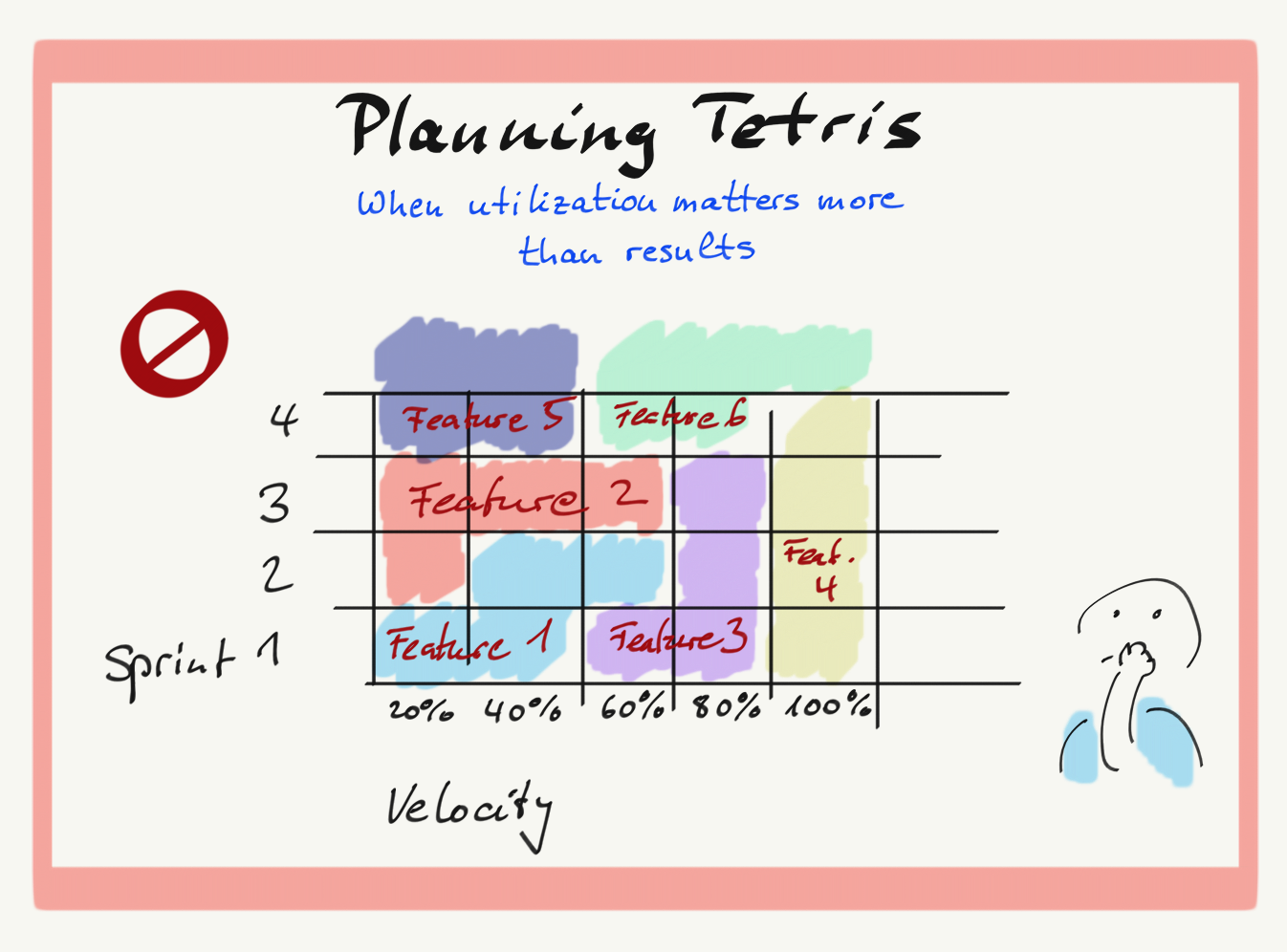
"We need to utilize all of our Story Points" - that's a common dysfunction in many Scrum teams, and especially in SAFe's Agile Release Trains where teams operate on a Planning horizon of 3-5 Sprints. It results in an antipattern often called "Planning Tetris." It's extremely harmful, and here's why.
Although the above feature plan appears to be perfectly optimized, reality often looks different: all items generate value later than they potentially could - at a higher cost, in longer time and with lower efficiency!
Accumulating Work in Process
Planning Tetris often leads to people starting work on multiple topics in one Sprint, and then finishing it in a later Sprint. It is resource-efficient (i.e. maximizing the utilization of available time), not throughput-efficient (i.e., maximizing the rate at which value is generated.)
That leads to increased Work in Process, which is a problem for multiple reasons:
Value Denial
Just like in the sample diagram above, "Feature 1" and "Feature 2" could each be finished in a single Sprint. And still, Feature 1 doesn't provide any value in Sprint 1, and Feature 2 has no value in Sprint 2. So, we lose 1 Sprint of marketability on Feature 1 (our highest priority) - and on Feature 2 as well:
A perfect example how utilizing the team makes the value come later!
Loss of money
Imagine now that every feature costs less than it's worth (which it should, otherwise it wouldn't be worth developing) - and you see that the "saved" efficiency of having worked on features 3 and 4 before finishing feature 1 costs the company more money than the added benefit .
Efficiency loss
You may argue, "different people are working on the features, so there's no multitasking."
Yes - and no. What is happening?
Sprint Planning for Sprint 1 has to discuss 3 features: 1,3 and 4. This means that the whole team is discussing three different topics, (none of which will be delivered in that Sprint.) The same happens in Dailies and Review. And, potentially at a source code level as well. The feature interference may also bloat up the complexity of technical configuration, deployment processes and the like.
The team becomes slower, hence less efficient.
Adding needless risk
In statistics, there's a phenomenon called "the high probability of low probability events." Let me explain briefly: There's an infinite amount of almost infinitely-unlikely events, but unfortunately, high infinity divided by low infinitiy is still a number close to one: Something will happen. You just don't know what, and when, so you can't prepare or mitigate. Since you don't know which aspect of your plan will be affected when a risk hits, you'll always be caught by surprise.
How is that a bigger problem in Planning Tetris than in sequentialized delivery?
Massive ripple effect
When you're working on one topic, and an event hits that affects your entire team, you have one problem to communicate. When the same happens as you're working on multiple topics, all of them are impacted, and you're generating a much stronger ripple effect.
Complex mitigation
As multiple topics are in process, you suddenly find yourself mitigating multiple topics. And that means multiplicative mitigation effort - less time to work, and at the same time a higher risk that not all mitigations are successful. You end up with a higher probability of not being able to get back on track!
Chaotic consequences
Both the ripple effect into the organization and the mitigating actions could lead to unpredicted consequences which are even harder to predict than the triggering event. In many cases, the only feasible solution is to surrender and mark all started topics as delayed, and try to clean up the shards from there.
Prepare to Fail
There's Parkinson's Law - "work always extends to fill the amount of time available." That's often used as an argument to start another topic, because it stops gold-plating and keeps people focused.
But there's also the (F)Law of Averages: "Plans based on averages fail half the time."
The latter makes planning tetris a suicidal approach from a business perspective: it starts a vicious circle.
Predictable failure
Because there's no slack built into planned tetris, the mid-term plan will automatically fail as soon as a single feature turns out more complex than planned. The more features are part of our tetris stack, the more likely at least one of them will fail. And the team will usually get blamed for it. Because of that, we end up with
Conservative estimates
Teams must allocate the slack buffers into their feature estimates to reduce the probability of failure. When a Tetris plan spans multiple Sprints, some feature content may not be "Ready" for implementation during the Sprint when slack would be available - so we end up with Parkinson's Law, the buffered estimates don't reduce failure probabilities.
Declining throughput
At this point, Parkinson's Law tag-teams with the Flaw of Averages to KO the team: Regardless of how conservative the estimates, the team will still end up failing half the time. The consequence is that business throughput continues to decline (there's an interesting bottom: when a Sprint only contains one feature!)
Strangulating the team
Let's take a look at the psychological impact of Planning Tetris now as well:
No space for Creativity
I have never seen an organization where Product Management was happy that developers would add "creative spaces" into a Tetris Plan. It's all about churning out feature, after feature, after feature, without a pause, without a break. When one feature is done, another is already in progress. There is no room to be creative.
No space for Growth
The only relevant business outcome in Tetris Plans is usually business value delivered. It ignores that developers are the human capital of the organization, and growing them is growing the organization's ability to deliver value. Especially in the rapidly changing tech industry, not growing equals falling back until eventually, the team is no longer competitive.
No space for Improvement
I often advise that developers should take some time to look at "Done" work to reflect how it could have been done better, and turning that better way into action. With Planning Tetris, that opportunity doesn't exist - another feature is waiting, and improving something that exists is always less important than delivering the next big thing. That often ends in terrible products which are no joy to deal with - for developers and customers alike!
Now ... what then?
The point that Planning Tetris is a terrible idea should be blatantly obvious.
"Now what's the better way then?" - you may ask.
It sounds incredibly simplistic, because it is actually that simple.
Reduce the amount of features the team is working on in parallel to an absolute minimum. This minimizes blast radius.
Instead of having people parallelize multiple topics, let "inefficient", "not-skilled" people take easier parts of the work to step up their game. That reduces the impact of low-probability events and gives everyone air to breathe.
Put slack into the Sprints. The gained resilience can absorb impact. It also reduces the need for buffered estimates, countering Parkinson's Law and the Flaw of Averages. It also gives people air to breathe.
Agree on Pull-Forward. When the team feels idle, they can always pull future topics into unused idle time. Nobody complains when a topic is finished ahead of time, everyone complains when something turns late. Pull Forward has no ripple effects or chaotic consequences.
In strongly plan-driven organizations, we often see a fascination with Sprint Predictability. So - what is it, and why would I advise against it?
Let's first take a look at how we can measure Sprint Predictability:
We have four key points of interest in this measurement system:
What did the team plan based on their known/presumed velocity?
What did the team actually deliver based on their committed plan?
What did the team miss, based on their committed plan?
What did the team overachieve?
Charted, it could look like this:
We can thus tell whether a team can estimate their velocity realistically, and whether they are setting sufficiently SMART (Specific, Measurable, Ambitious, Realistic, Terminated) goals for themselves.
In a multi-team setting, we could even compare these metrics across teams, to learn which teams have a good control over their velocity and which don't.
If by now, you're convinced that Sprint predictability is a good idea - no! It's not! It's a horrible idea!
Here's why:
The Crystal Ball
Every prediction is based on what we know today. The biggest challenge is predicting things we don't know today.
Here are a couple reasons why our forecast of predictability may be entirely wrong and why we may need to adapt. We may have ...
Vague objectives
Mis-estimated the work
Made some assumptions that turned out false
Encountered some unforseen challenges
Discovered something else that has higher value
Of course, management in a plan-driven organization can and will argue, "That's exactly the point of planning: to remove such uncertainties and provide clarity." With which we are back to square 1: Trying to create the perfect plan, which requires us to have a perfect crystal ball.
Predictability implicitly assumes that adaptation (ability to respond to change) is a luxury rather than a necessity. When we operate in an environment where adaptation really isn't required, we should not use an agile approach to begin with.
Let's now take a tabular look at the five reasons for getting forecasts wrong:
Cause
Challenge
Alternative
Vague objective
The communicated objective and the real goal may be miles apart. It's better to pursue the actual goal than to meet the plan.
Take small steps and constantly check whether these are steps in the right direction, changing course as new information arises.
Mis-estimation
Work was perceived simpler than originally thought, mandating tasks nobody expected, consuming extra time.
Avoid aligning on the content of the work, instead align around the outcomes and break these into bite-sized portions that have little risk attached.
Wrong assumptions
Some things about our Product turned out differently than we had anticipated. We can do more pre-work, which does nothing other than trade "delivery time" for "preparation time", we still make un-validated assumptions.
Validating assumptions is always a regular part of the work. Set up experiments that determine the next step rather than trying to draw a straight line to the goal from the beginning. Accept "open points" as you set out.
Unforseen challenges
An ambitious plan has risk, while an un-ambitious plan has risk buffers. Pondering all of the eventualities to "right-size" the risk buffer is a complete distraction from the actual Sprint Goal.
Equally avoid planning overly optimistic (e.g., assuming absolutely smooth sailing) as well as overly pessimistic (e.g. assuming WW3 breaks out) and just accept that unusual events take us out of our comfort zone of being predictable. Learn over time which level of randomness is "normal."
Value changed
Something happened that made new work more valuable than the one originally planned. While this shouldn't frequently happen within a Sprint, it could be part of discovery work.
Ensure there is clarity within the team and organization that the primary goal is maximizing value and customer satisfaction, not meeting plans.
As we can see from the above table, "Sprint Predictability" is a local optimization that gives people a cozy feeling of being fully in control, when in reality, they're distracted from creating value for the organization.
Re-Focous
As much as managers, and even some Scrum Masters, like to use metrics and numbers to see whether teams have high predictability on their Sprints, we need to re-focus our discussion towards:
How well do we understand which goal we're trying to achieve? (Level of Transparency)
Do we understand, and have the ability to generate, value? (Ability to Inspect)
Since "The biggest risk is taking no risks" - let's agree on how much risk can our organization bear with (Ability to Adapt)
When we focus on these pillars of Scrum, we will go an entirely different direction from "becoming more predictable" - we need to improve our ability to respond swiftly and effectively as new information arises!
And once we have high responsiveness, we can argue formidably whether a "Sprint Predictability Index" has any value at all.
There's a common backlog prioritization technique, suggested as standard practice in SAFe, but also used elsewhere, "WSJF", "Weighted Shortest Job First." - also called "HCDF", "Highest Cost of Delay First" by Don Reinertsen.
Now, let me explain this one in (slightly oversimplified) terms:
The idea behind WSJF
It's better to gain $5000 in 2 days than to gain $10000 for a year's work.
You can still go for those 10 Grand once have 5 Grand in your pocket, but if you do the 10 Grand job first, you'll have to see how you can survive a year penniless.
Always do the thing first that delivers the highest value and blocks your development pipeline for the shortest time. This allows you to deliver value as fast and high as possible.
How to do WSJF?
WSJF is a simple four-step process:
To find out what the optimal backlog position for a given item is, you estimate the impact of doing the item ("value") and divide that by the investment into said item ("size") and then put the items in relation towards each other.
It's often suggested for estimated to use the "Agile Fibonacci" scale, so "1, 2, 3, 5, 8, 13, 20, 40, 80..."
The idea is that every subsequent number is "a little more, but not quite twice as much" as the previous one, so a "13" is "a little more than 8, but not quite 20".
Since there are no in-between numbers, when you think you're not sure whether an item is 8 or 13, you can choose either, because these two numbers are adjacant and their difference is considered miniscule.
Step 1: Calculate "Value" Score for your backlog items.
Value (in SAFe) is actually three variables: User and/or Business Value, Time Criticality, Enablement and/or risk reduction. But let's not turn it into a science. It's presumed value.
Regardless of how you calculate "Value", either as one score or a sum or difference of multiple scores, you end up with a number. It becomes the numerator in your equation.
Step 2: Calculate "Size" Score for your backlog items.
"Size" is typically measured in the rubber-unit called Story Points, and regardless of what a Story Point means in your organization or how it's produced, you'll get another number - the denominator in your equation.
Step 3: Calculate "WSJF" Score for your backlog items.
"WSJF" score, in SAFe, is computed by dividing Value by Size.
For example, a Value of 20 divided by a size of 5 would give you a WSJF score of 4.
Step 4: Sort the backlog by "WSJF" Score.
As you add items, you just put them into the position where the WSJF sort order suggests, with the highest value on top, and the bottom value on the bottom of the backlog.
For example, if you get a WSJF of 3 and your topmost backlog item has a WSJF score of 2.5, the new item would go on top - it's assumed to be the most valuable item to deliver!
And now ... let me dismantle the entire concept of WSJF.
Disclaimer: After reading the subsequent portion, you may feel like a dunce if you've been using WSJF in the real world.
WSJF vs. Maths
WSJF assumes estimates to be accurate. They aren't. They're guesswork, based on incomplete and biased information: Neither do we know how much money we will make in the future (if you do, why are you working in Development, and not on the stock market?) nor do we actually know how much work something takes until we did it. Our estimates are inaccurate.
Two terms with error
Let's keep the math simple, and just state that every estimate has an error term associated. We can ignore an estimator's bias, assuming that it will affect all items equally, although that, too, is often untrue. Anyway.
The actual numbers for an item can be written as:
Value = A(V) + E(V) [Actual Value + Error on the Value]
Sizes = A(S) + E(S) [Actual Size + Error on the Size]
Why is this important?
Because we divide two numbers, which both contain an error term. The error term propagates.
For the following section, it's important to know that we're on a Fibonacci scale, where two adjacent items are always at least 60% apart.
Slight estimation Error
If we over-estimate value, an item will have at least 60% higher value than estimated, even if the difference between fact and assumption is miniscule. Likewise, if we under-estimate value, an item will have at least 30% lower value than estimated.
To take a specific example:
When an item is estimated at 8 (based from whatever benchmark), but turns out to actually be 5, we overestimated it by 60%. Likewise, if it turns out to actually be 13, we underestimated it by 38.5%.
If we're not 100% precise on our estimates, we could be off by a factor of 2.5!
The same holds true for Size. I don't want to repeat the calculation.
Larger estimation error
Remember - we're on a Fibonacci scale, and we only permitted a deviation by a single notch. If now, we permit our estimates to be off by two notches, we get significantly worse numbers: All of a sudden, we could be off by a factor of more than 6!
Now, the real problem happens when we divide those two.
Square error terms
Imagine that we divide a number 6 times larger than it should be, by a number 6 times smaller than it should be, we get a square error term.
Let's talk in a specific example again:
Item A was estimated as 5 value, but it was actually a 2 value. It was estimated as 5 size, but it was actually a 13 size. As such, it had an error of 3 in value, and an error of 13 in size.
Estimated WSJF = (2 + 3) / (13 - 8) = 1
However, the Actual WSJF = 2 / 13 = 0.15
Now, I hear you arguing, "The actual numbers don't matter... it's their relationship towards one another!"
Errors aren't equal
There's a problem with estimation errors: we don't know where we make errors, otherwise we wouldn't make them, and we also make different errors, otherwise, they wouldn't affect the scale at all. Errors are errors, and they are random.
So, let me draw a small table of estimates produced for your backlog:
Item
Est. WSJF
Est. Value
Est. Size
Act. Value
Act. Size
Act. WSJF
A
1.6
8
5
5
5
1
B
1
8
8
3
20
0.15
C
0.6
3
5
8
2
4
D
0.4
5
13
13
2
6.5
Feel free to sort by "Act. WSJF" to see how you should have ordered your backlog, had you had a better crystal ball.
And that's the problem with WSJF
We turn haphazard guesswork into a science, and think we're making sound business decisions because we "have done the numbers", when in reality, we are the victim of an error that is explicitly built into our process. We make entirely pointless prioritization decisions, thinking them to be economically sound.
WSJF is merely a process to start a conversation about what we think should be priority, when our main problem is indecision. It is a terrible process for making reliable business decisions, because it doesn't rely on facts. It relies on error-prone assumptions, and it exacerbates any error we make in the process.
Don't rely on WSJF to make sound decisions for you.
It's a red herring.
The discussion about where and what the value is provides much more benefit than anything you can read from a WSJF table. Do the discussion. Forget the numbers.
While predictability is pretty important for management, and having an agile team/organization deliver in a predictable manner is certainly aspirable, setting targets for predictability is a terrible idea. And here's why:
Blue lines are reinforcing, red lines negative reinforcement, orange items are under the teams' control.
As soon as we set Predictability as a target, we create a reinforcement loop that rewards teams for spending more time planning and less time actually developing. The same reinforcement loop also destroys the very thing called "agility", i.e. the flexibility of "responding to change over following a plan."
As a consequence of both reinforcement loops initiated by setting a predictability target, we reduce the ability to actually deliver business value. As such:
Developers who work towards a Predictability objective do so at the expense of Business Objectives.
If that's not yet clear enough, let me put it bluntly:
Predictability targets hurt your company's bottom line.
Hence, I will strongly advise to resist the urge of using predictability as a KPI and setting predictability targets on software development.
At the risk of stating something that is already obvious - "#noestimates" does not mean "We don't have any idea what we're building or how much it costs". It means we have simplified the process to a point where risk and reward are in a sound correlation. There are many ways to reach a state where estimates are no longer relevant. Here, we will discuss Backlog Slicing and its effect on estimation.
One way to remove the need for estimation is to slice deliverables into packages no bigger than 1 single day: At worst, you have lost 1 day and learned that in 1 day.
When you can do this slicing for any given backlog item within a couple minutes, it becomes completely irrelevant whether the slice is actually 1 minute or 8 hours, since the Law of Big Numbers starts to kick in at some point and it becomes fair to say that a deliverable is about 4 hours.
So, even with #noestimates we actually do have an estimate, but we don't bother going through all of the items individually, attaching a "4 hour, could be more or less" label to each and every one of them.
With this information, we can also predict cost and duration:
How many slices do we get out of a "requirement"? 1, 20, 1000? How many of them are really needed?
Then we optimize: Can we deliver the bulk of the value by doing only a couple of them?
Lastly, we can quickly observe and act: Do we consistently deliver an about even amount of slices per week? Does the number increase or decrease? Are there any significant outliers that clog the pipeline?
By observing the answer to this question, we imply data without actually measuring it:
As long as the consistent flow of delivery is there and there are no outliers, there is no problem.
On the other hand, when we seem clogged or bogged down, we realize this immediately, because we're not delivering any more.
This becomes visible and can be fixed within a couple of days, so we can go without a company-wide measuring system that may tell us the obvious by the time the team is already working on a solution - or even worse, waste precious development time by holding the team accountable to solve a problem that we can't influence.
Summary
#noEstimates is not equal to abolishing good business practice due to negligence or inability.
Much rather, #noEstimates is a sensible step of evolution for developers who have mastered their technical domain, whose Product Owner is crystal clear on business value and priorities - and for people with a very rigorous and keen Continuous Improvement mindset.
A team avoiding Estimates without these three aspects in place may act haphazard.
So, #noEstimates is effectively "Implicit Estimates without explicit estimation overhead".
Many Scrum teams struggle with Planning Poker and it's proper use. A recurring question is: "Can't we just use hours instead?". A mistake some teams make is converting the Points back into Man-Days.
The purpose of Planning Poker
Sprint Planning should contain a C-C-C process (Card, Conversation, Confirmation). In brief:
1 - the PO displays what they want
2 - the team can probe whether they understand the idea in the same way
3 - the team discusses how they want to approach the topic,
4 - Everyone agrees that this is what will be done.
5 - Rinse, repeat until the team decides their capacity is reached.
Estimation in Story Points is used to quantify complexity of the task. It is actually expected that estimates vary until the team has reached a certain agreement on the complexity.
Disregarding the accuracy of an estimate, a precise discussion of the factors contributing to complexity will bring the team's estimates closer to each other.
An example dialogue during Planning Poker
The Product Owner introduces the new Widget that will shoot our sales through the roof. Tim estimated a 20, Jane estimated a 3. Jane reasons: "All we need is to build some plastic device, put a chip on it and contact our service URL."
Tim then turns to the PO, "So, you expect the Widget to be usable from anywhere?" - "Yup" - "Even when no Wi-Fi is available?" - "Yup." - "Can we build a first version assuming Wi-Fi is present?" - "Yup." - the precision increased, but the Story has already been split into two pieces. Also, everyone on the team now understands why Tim had serious reservations about the complexity of the issue.
While Tim may now agree with Jane regarding the estimate for the first version, Jane may now also have serious reservations about the second stage, because nobody knows how complex this issue gets if "everywhere" also includes underground, in the absence of cellular and satellite signals.
Estimation is for Innovation
One of the first things which classic project managers must get used to is the idea that software development, as the name indicates, is development. Development is not just working according to plan, but the creation of something which was not in existence before.
Software is always new: If we use something existing, we simply buy and/or include it. But we don't build it. If we build it, it's new. This means, nobody has done it before - or, at least, not exactly in the same way that we need it.
How can you know how long something takes that nobody has done before?
You can't - and this is why at best, we estimate, not a detailed forecast.
Let's estimate
To give you some understanding of the difference between an estimate and the quantification of an effort forecast, let's play a game.
As a Product Owner, I have great visions and would ask you to do some estimation for me.
Here are 5 items which will bring great value to mankind:
Cure for Cancer
Immortalism
Cold Fusion
Warp Engine
Terraforming
Now, I would like you to estimate these items for me. You can probably come up with a numbering between 1 and 20 for these items, where "1" is the least complex and "20" the most complex issue.
Almost intuitively, your numbering approach will probably revolve mostly about your understanding of the domain as well as the uncertainty you have. The actual "work to do" will probably play a miniscule role.
Estimates are not Man-Days
Can you now assign hours/months/years to each of these items?
In principle, the problem is identical to Software Development: We may have a certain (hopefully, more intricate) understanding of the domain, but we have never done that exactly same thing before.
We will not know which solution is correct until the solution is correct and in place.
Since the course of action is prone to change due to any new information we gain while we are working, it makes little sense to plan a specific course of action. Every step depends on the last step taken, and every result either encourages or discourages the next step we had in mind. Sometimes, next steps only become obvious once a specific result has been obtained.
Summary
The purpose of Planning Poker is the facilitation of discussion about complexity and uncertainty. We care for having a common understanding and dealing with the "known unknown". Removing any last bit of uncertainty about the issue might require more effort than actually coming up with a working solution, so we simply accept this uncertainty.
If the work is totally
clear, the item is most likely quite small. When things interact, start
to
depend or become unclear - numbers will increase. A numerical estimate
therefore indicates complexity and uncertainty, not work to do.
We purposefully de-scope capacity planning, because we understand
that as soon as numbers increase, there will always be a rather high
residual error. We value working software over guesswork numbers, so we
only estimate enough to know what we intend to do - not what we will be doing for certain.
We may have hindsight 20-20, but regarding the future, we will always be guessing.