Whether you're transitioning towards agile ways of working on a Legacy platform or intend to step up your testing game for a larger system developed in an agile fashion, at some point, it pays to set up a Coverage Matrix to see where it pays to invest effort - and where it doesn't.
Before we start
First things first: the purpose of an agile Coverage Matrix isn't the same as a traditional project-style coverage matrix that's mostly concerned with getting the next release shipped. I don't intend to introduce a mechanism that adds significant overhead with little value, but to give you a means of starting the right discussions at the right time and to help you think in a specific direction. Caveat emptor: It's up to you to figure out how far you want to go down each of the rabbit holes. "Start really simple and incrementally improve" is good advice here!
What I'm proposing in this article will sound familiar to the apt Six Sigma practitioner as a simplified modification of the method, "Quality Function Deployment." And that's no coincidence.
Coverage Characteristics
Based on the ISO/IEC 9126, quality characteristics can be grouped into Functionality, Reliability, Usability, Efficiency, Maintainability and Portability. These are definitely good guidance.
To simplify matters, I like to start the initial discussion by labelling the columns of the matrix:
- Functionality ("Happy Cases")
- Reliability ("Unhappy Cases")
- Integration
- Performance
- Compliance
- UX
Of course, we can clarify a lot more on what each of these areas means, but let's provide some leeway for the first round of discussion here. The most important thing is that everyone in the room has an aligned understanding on what these are supposed mean.
If you are in the mood for some over-engineering, add subcategories for each coverage characteristic, such as splitting Performance into "efficiency", "speed", "scalability", "stress resilience" etc. That will bloat up the matrix and may make it more appropriate to flip rows and columns on the matrix.
Test Areas
Defining test areas falls into multiple categories, which correlate to the "Automation Test Pyramid".
- User journeys
- Data flow
- Architectural structure
- Code behaviour
There are other kinds of test areas, such as validation of learning hypotheses around value and human behaviour, but let's ignore these here. Let's make a strong assumption that we know what "the right thing" is, and we just want to test that "we have things right." Otherwise, we'd open a can of worms here. You're free to also cover these, adding the respective complexity.
Functional areas
In each test area, you will find different functional areas, which strongly depend on what your product looks like.
User journeys
There are different user journeys with different touchpoints how your user interacts with your product.
For example, a simple video player app might have one user flow for free-to-play, another for registration, another for premium top-up, and another for GDPR compliant deregistration as well as various flows such as "continue to watch my last video" or "download for offline viewing". These flows don't care what's happen technically.
Data flow
Take a look at how the data flows through your system as certain processes get executed. Every technical flow should be consistent end-to-end.
For example, when you buy a product online, the user just presses "Purchase", and a few milliseconds later, they get a message like "Thank you for your order." The magic that happens inbetween is make or break for your product, but entirely irrelevant for the user. In our example, that might mean that the system needs to make a purchase reservation, validate the user's identity and their payment information, must conduct a payment transaction, turn the reservation into an order, ensure the order gets fulfilled etc. If a single step in this flow breaks, the outcome could be an economic disaster. Such tests can become a nightmare in microservice environments where they were never mapped out.
Architectural structure
Similar to technical flow, there are multiple ways in which a transaction can occur: it can happen inside one component (e.g. frontend rendering), it can span a group of components (e.g. frontend / backend / database) or even a cluster (e.g. billing service, payment service, fulfilment service) and in the worst case, multiple ecosystems consisting of multiple services spanning multiple enterprises (e.g. Google Account, Amazon Fulfilment, Salesforce CRM, Tableau Analytics).
In architectural flow, you could list the components and their key partner interfaces. For example:
Architectural flow is important in the sense that you need to ensure that all relevant product components and their interactions are covered.
You can simplify this by first listing the relevant architectural components, and only drilling down further if you have identified a relevant hotspot.
Code behaviour
At the lowest level is always the unit test, and different components tend to have different levels of coverage - are you testing class coverage, line coverage, statement coverage, branch coverage - and what else? Clean Code? Suit yourself.
Since you can't list every single behaviour of the code that you'd want to test for without turning a Coverage Matrix into a copy of your source code, you'll want to focus on stuff that really matters: do we think there's a need to do something?
Bringing the areas together
There are dependencies between the areas - you can't have a user flow without technical flow, you won't have technical flow without architectural flow, and you won't have architectural flow without code behaviour. Preferably, you don't need to test for certain user flows at all, because the technical and architectural flows already cover everything.
If you can relate the different areas with each other, you may learn that you're duplicating or missing on key factors.
Section Weight
For each row, for each column, assign a value on how important this topic is.
For example, you have the user journey "Register new account." How important do you think it's to have the happy path automated? Do you think the negative case is also important? Does this have impact on other components, i.e. would the user get SSO capability across multiple products? Can you deal with 1000 simultaneous registrations? Is the process secure and GDPR compliant? Are users happy with their experience?
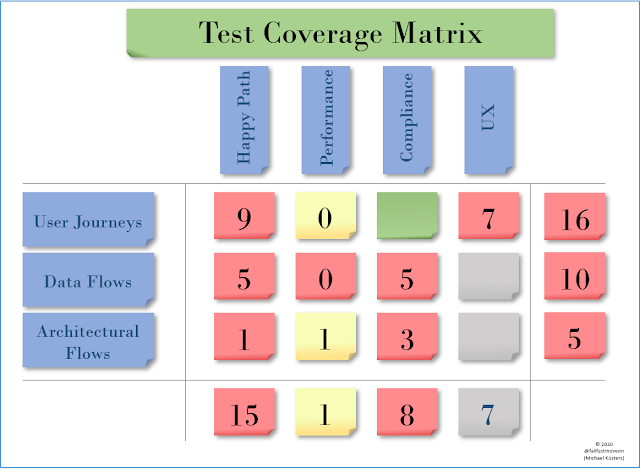
You will quickly discover that certain rows and columns are "mission critical", so mark them in red. Others will turn out to be "entirely out-of-scope", such as testing UX on a backend service, so mark them gray. Others will be "basically relevant" (green) or "Important" (yellow).
As a result, you end up with a color-coded matrix.
The key discussion that should happen here is whether the colors are appropriate. An entirely red matrix is as unfeasible as an entirely gray matrix.
 |
| A sample row: Mission critical, important, relevant and irrelevant |
Reliability Level
As the fourth activity, focus on the red and yellow cells and take a look at a sliding scale on how well you're doing in each area and assign a number from 0 to 10 with this rough guidance:
- 0 - We're doing nothing, but know we must.
- 3 - We know that we should to more here.
- 5 - We've got this covered, but with gaps.
- 7 - We're doing okay here.
- 10 - We're using an optimized, aligned, standardized, sustainable approach here.
As a consequence, the red and yellow cells should look like this:
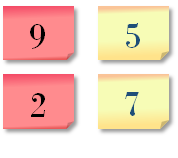 |
| A sample matrix with four weighted fields. |
As you would probably guess by now, the next step for discussion would be to look at the big picture and ask, "What do we do with that now?"
The Matrix
Row Aggregate
For each row, figure out what the majority of colors in that row is, and use that as the color of the row. Next, add up all the numbers. This will give you a total number for the row.
This will give you an indicator which row is most important to address - the ones in red, with the lowest number.
 |
| The Row Aggregate |
Column Aggregate
You can use the same approach for the columns, and you will discover which test type is covered best. I would be amazed if Unhappy Path or Compliance turn out to have poor coverage when you first do this exercise, but the real question is again: Which of the red columns has the lowest number?
After conducting all the above activities, you should end up with a matrix that looks similar to this one:
|
| A coverage matrix |
Working with the Matrix
There is no "The right approach" to whether to work on improving coverage for test objects or test types - the intent is to start a discussion about "the next sensible thing to do," which totally depends on your specific context.
As per our example, the question of "Should we discuss the badly covered topic Performance which isn't the most important thing, or should we cover the topic of architectural flow?" has no correct answer - you could end up with different groups of people working hand in hand to improve both of these, or you could focus on either one.
How-To Use
You can facilitate discussions with this matrix by inviting different groups of interest - business people, product people, architects, developers, testers - and start a discussion on "Are we testing the right things right, and where or how could we improve most effectively?"
Modifications
You can modify this matrix in whatever way you think: Different categories for rows or columns, drill-in, drill-across - all are valid.
For example, you could have a look at only functional tests on user journeys and start listing the different journeys, or you could explicitly look at different types of approaching happy path tests (e.g., focusing on covering various suppliers, inputs, processing, outputs or consumers)
KISS
This method looks super complicated if you list out all potential scenarios and all potential test types - you'd take months to set up the board, without even having a coversation. Don't. First, identify the 3-4 most critical rows and columns, and take the conversation from there. Drill in only when necessary and only where it makes sense.


