Do we even need "Agile" to improve time-to-market, reducing cost and increasing success rates? After reading this article, you may have doubts.
Do these statements sound familiar to you?
- Software Development is too expensive
- We are lagging years behind the demand.
- Too many initiatives (projects etc.) fail.
The solution? Scrum. No, just kidding. Scrum doesn't have a solution there. Neither does LeSS or SAFe. Or XP, or any other "Agile Framework" that focuses on the development part of an organization. The solution rests in how we think about organizing our products long before developers actually get involved.
Too many "Agile Transformation" initiatives are focused on the output of software development and forget the big picture of the system in which they are operating.
The Product Development Funnel
Take a look at this abstract development funnel. Every organization works somehow like this, while the slope of the funnel and the processes in each stage may vary widely.
Let us examine the core concepts of this funnel.
To keep this article at least somewhat simple, let us equivocate "product" and "product portfolio" - because from a certain level of abstraction, it's irrelevant whether we have one product or an entire portfolio thereof: both capacity and capability are still finite.
Likewise, let us ignore the entire dispute around Lean/Agile vs traditional program and/or portfolio management, because irrespective of how you do it, you are still dealing with demand, choosing opportunities and prioritizing effort.
Customer Demand
Whether our customers are people out there on the market who purchase our product, or internal stakeholders of our product, there are always unmet needs. The amount of unmet needs that our product could meet is the amount of potential work that is still required, and that's potentially infinite - unlike our funding and capacity.
At the expense of taking a grossly oversimplified definition here, let us define "Marketing" as the effort invested into making others aware of potential needs and wants - and in return, becoming aware of what these are.
Oddly enough, even delivery is a marketing activity in some sense: as people use the product, they become more aware of additional needs. Hence, the old economic rule, "supply creates its own demand" ensures that the demand part of the funnel will never dry up in a well-run product.
Development portfolio
Every demand that's deemed sufficiently important will eventually end up in some kind of portfolio, the known list of undone upcoming work. This is where the first stage of filtering occurs. Filter mechanisms include product strategy, economic viability or even internal politics. The specific reasons for filtering are irrelevant in this context.
Every item that lands in the portfolio will subsequently put stress on the development organization. In an odd twist of fate, the worse an organization's ability to manage the portfolio, the lower the satisfaction with the developed product will eventually be, irrespective of how good or bad development was.
The reason is simply because once the capacity of the development organization is exceeded, accepting further demand will not yield better outcomes.
Running Initiatives
Once a portfolio item has been scoped for development, it will become a development initiative. Organizations do have this habit of finding it easier to start initiatives than to complete them. Every initiative started will eventually result in one of three states: Live (successfully delivered), Dead (descoped without delivery) - or Undead (lingering in a limbo state where people are waiting for results that may never come).
Let's briefly examine Live and Dead: An initiative that goes "Live" is the only type of initiative that results in something called "Business Value", or even potentially positive Return on Invest. It's therefore highly desirable to get initiatives live.
A Dead initiative is an initiative that has been terminated before it has generated business value. Every cent spent on dead initiatives was waste. Completing an initiative with a negative ROI is just throwing the good money after the bad, so killing them is still the better alternative.
The biggest problem though, are neither Live or Dead initiatives - it's the Undead: An organizational culture that doesn't have the willingness to kill initiatives that have exceeded their life expectation will generate and accumulate undead initiatives.
The problem with these undead initiatives is that they drain your organization's energy. People spend time and effort to work on and track the Undead, and this time isn't available to get other initiatives Live, so they turn otherwise healthy initiatives into Undead as well. Talk about Zombie Apocalypse!
The health of a product development organization can easily be measured by how many Undead Inititiatives they permit - every initiative ever started that was not clearly terminated or completed. The easiest, yet oftentimes most uncomfortable, fix to increase this health is by taking inventory and killing all the zombie initiatives.
Delivery Capability
The delivery capability is the one place where a common "Agile Transformation" focuses. The expectation is that somehow, magically, the adoption of daily standups, cadenced plannings, reviews and retrospectives will improve performance. It doesn't. (At least, not significantly - unless your developers are really stupid, which I claim they aren't.) And, on a more abstract level, the expectation is that this approach will somehow improve the ratio of met versus unmet demand. It doesn't.
It might look like a good idea thus to increase the capacity of the development process, i.e. add more developers or provide better tools and extra resources to make developers more efficient. It isn't.
What sounds good in theory often results in proportionately increased expectations: When development capacity is increased through additional funding, the organization will expect to be able to launch more initiatives - and thus, the problem persists. It might even get worse, but that's another story, to be told at another time.
Retrospectives and change initiatives focused on "how can we do better in delivering" might completely miss the point if the development organization is in a state of continuous overburden: the overburden will never go away as long as more demand enters the system than what can be delivered.
Everything these frequent events accomplish is that the constant pressure to deliver creates psychological stress and eventually developers burn out: Development performance may even decline!
Let's talk about waste
In this section, let us move backwards through the funnel, as the waste accumulates throughout the funnel, like a clogged pipe. We have to unclog it where the blockage is caused, rather than where it occurs.
Wasted development effort
What should developers spend time on? Developing working solutions, obviously. Yet, developers often spend significant portions of their time doing things not related to this. Let's take a crude tally:
- Status meetings for all those running initiatives.
- Especially the zombies.
- Task switching effort between those initiatives.
- Waiting for input on an initiative.
- Catching up with changing requirements in an initiative.
The sum of all the effort invested into these items is the "low hanging fruit" in any optimization strategy. Reducing the amount of running initiatives reduces the amount of wasted development effort, thus increasing available capacity to get meaningful work done.
Kanban addresses this by limiting Work-in-Progress (WIP), although this only helps when we limit WIP at a higher level, that is: we must control the influx of initiatives, not the amount of development tasks, in order to gain any benefits.
Scrum addresses this by limiting the amount of items a team takes on during a Sprint - however, this is not a fix when more portfolio initiatives get started than completed: the consequence is an ever-growing product backlog. The problem is hidden, not solved.
In the ideal Scrum, the Scrum Team has full control over the entire product development funnel. Since this would require the organization to have moved from cost accounting to throughput accounting, from funding work to funding teams and towards an integrated cross-functionality that puts business acumen into the Scrum Team - this is a type of Scrum most organizations don't have. Again, this implies that the improvement potential then doesn't relate to delivery.
Coordination Waste
The second stage of organizational waste occuring in product development is the coordination of initiatives. That's where we get project managers and matrix organizations from, and it's the reason why developer's calendars are cluttered with appointments. As every initiative has someone in charge, for simplicity's sake, let's call them "Initiative Owner". This initiative owner wants to be informed about what is going on and will take care that their initiative gets due attention.
If there is only one initiative, then all of an organization's efforts can focus on completing this one initiative.
Add another initiative, and the organization has to solve the problem of coordinating both the efforts between those initiatives - and to solve blockages in either initiative without blocking any other work. The effort required for these activities increases exponentially in complexity with each ongoing initiative.
This coordination overhead would not even exist if there was only one initiative. The time and money sunk into coordinating parallel initiatives is pure waste.
At this point, we already need to ask the question why we see value in having multiple parallel initiatives - and why we believe that the value of starting another initiative outweighs the waste caused thereby. Likewise, we can ask the question whether the reduction of initiatives reduces the waste by a level that warrants deferring, descoping or even discarding one or more initiatives.
As coordination waste is multiplicative on outcome throughput, the lever of optimizing coordination waste outweights the lever of optimizing team-level productivity.
Budget Waste
Every organization determines one way or another what will be developed. Regardless if this happens via a Product Owner prioritizing an item in a product backlog or a SteerCo starting a traditional project, at some point a decision will be made to start a new initiative. In one form or another, at this point, the organization makes an investment decision: budget is allocated to the initiative. The biggest waste of budget is to start an initiative that doesn't get completed. Any initiative started without sufficient delivery capacity to complete both the currently running and the new initiative, will predictably induce waste into the organization.
The simplest form of reducing budget waste is by deferring the decision about starting an initiative until there is sufficient free capacity within the organization to complete this initiative without impacting any other initiative.
As budget waste yields coordination waste, and coordination waste yields capability waste, the lever of reducing budget waste is even stronger than that of reducing coordination overhead.
Marketing waste
Probably the most well-hidden form of waste is demand waste, or "Marketing waste". Any form of demand that isn't eventually met by the product generates waste. The discovery, itemization and exploration of this type of demand generate cost without value. Having more demand than one can meet is only good because it creates options, yet one needs to be careful lest one loses focus in all of these options. There's even the economic dilemma of demand pull inflation where the mere prospect of additional demand will increase cost, but that's another story, to be told another day.
The simplest way of decreasing marketing waste is by limiting demand to a level where supply is at least still sensibly correlated to demand, and the organizational processes of managing demand are low effort.
Marketing waste propagates into the product organization at full force: Poorly defined or invalid value hypotheses block scarce downstream capacity, while an oversupply of demand leads to pressure on the system.
Limiting the waste
As heretical as this sounds, the most effective way of improving a development organization has nothing to do with improving development - and that's where all the team level agile approaches go wrong.
The most effective strategy for increasing effectiveness is by pulling the longest levers first:
- Limit the amount of initiatives within the development organization. To achieve this:
- Limit the influx of approved initiatives. To achieve this:
- Limit the rate at which demand is translated into initiatives. To achieve this:
- Limit the influx of demand into your organization.
"Do not try to do everything. Do one thing well."
- Steve Jobs
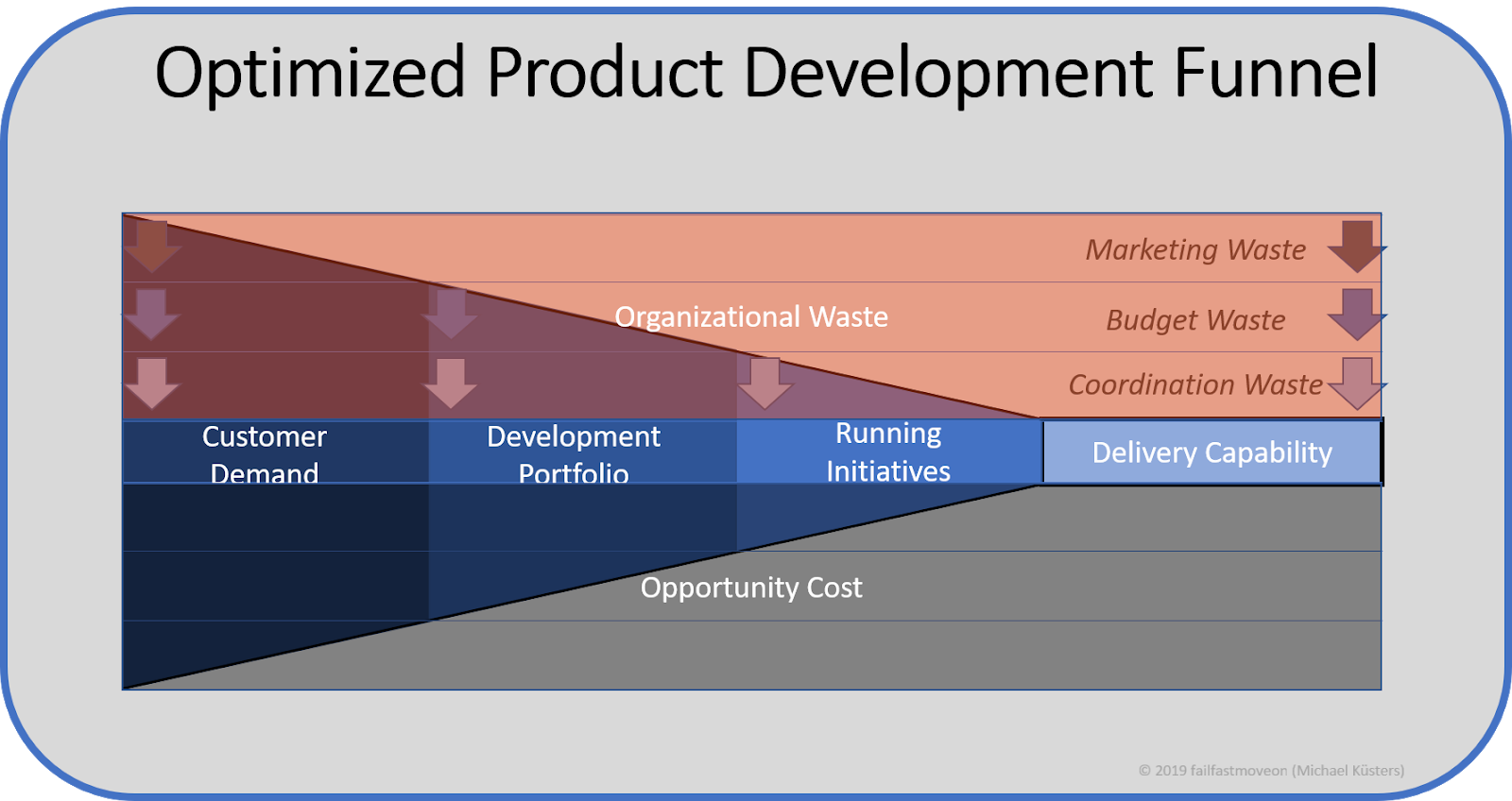
Here is an overview of what an organization's development funnel would look like if all settings were optimal:
The optimization in this context focuses on reducing the Organizational Waste not related to delivering Useful Products, and on the decrease of Opportunity Cost by eliminating the waste associated with pursuing low-value demand.
When we take into account Little's law, we realize that this optimization approach achieves:
- Reduced cost of meeting demands ("feature cost savings")
- Reduced Time-To-Market for features
- Increased Success rates of initiatives
Depending on how significant the associated waste and opportunity cost within an organization currently is, the leverage may be massive, while the organizational change (staffing, training, skill distribution etc.) is insignificant. All that's required is - thinking differently!
And the funniest part - we haven't even touched development!
Conclusions
1. Think about what you really need to optimize before looking at "Agile Frameworks" as a solution.
2. Change your thinking before optimizing the work.
3. Optimize what you work on before optimizing how you work.